


3月25日,2023中国发展高层论坛开幕,三六零(601360.SH,下称“360”)集团创始人周鸿祎以“人工智能与未来安全”为题发表主题演讲。

周鸿祎展示了AI绘图生成的自画像,以及由大语言模型生成的开场白。他将人工智能发展划分为三个阶段:人工智障、强人工智能、超级人工智能。周鸿祎认为,GPT-4已经拥有超人的能力,具有真正的智能。
预计,GPT-6到GPT-8人工智能将会产生意识,变成新的物种。在GPT-3.5的时候,周鸿祎预言它将长出“眼睛和耳朵”,目前GPT-4已经具有看图的能力,初步印证了周鸿祎的判断。随着GPT已经进化出了“手”和“脚”,能够通过接入互联网API拥有操控世界的能力。
|GPT-4进化太快,满分第一名通过大厂模拟面试
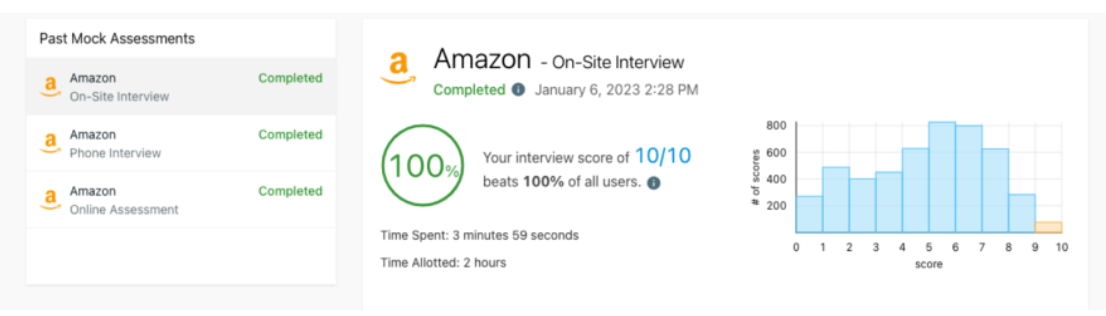
近日,GPT-4满分通过了LeetCode上的亚马逊公司模拟面试,超越所有参与测试的人类,可以被聘用为软件工程师。
GPT-4在这些方面表现大幅超越ChatGPT等之前模型,并在所有这些任务上惊人地接近人类水平,也就是摸到了AGI的门槛。
微软研究人员的这篇论文叫《通用人工智能的火花:GPT-4的早期实验》,在论文中他们写道,除了对语言的掌握之外,我们证明GPT-4还可以解决跨越数学、编码、视觉、医学、法律、心理学等领域的新颖而困难的任务,而无需任何特殊提示。
此外,在所有这些任务中,GPT-4的表现都非常接近人类水平,并且经常大大超过ChatGPT等先前的模型。鉴于GPT-4功能的广度和深度,可以合理地将其视为通用人工智能 (AGI)系统的早期(但仍不完整)版本。
为了证明他们的说法,研究人员让GPT-4证明素数是无限的,并且每一行都押韵,结果GPT-4完美地做到了!人类能做到吗?估计90%的人连素数是什么都不知道,50%的人连什么是押韵都不知道,要证明就更是望尘莫及的了。
虽然GPT-4在许多任务上达到或超过了人类水平,但总体而言,它的智力模式明显地不像人类。然而,GPT-4几乎可以肯定只是迈向一系列越来越普遍的智能系统的第一步。但即使是作为第一步,GPT-4也挑战了相当多的,广泛持有的关于机器智能的假设,并表现出突发行为和能力,且其来源和机制目前还很难准确辨别。
是不是有些毛骨悚然,脊背发凉?GPT-4的智力模式不像人类,其来源和机制目前还很难准确辨别。这是不是意味着GPT-4在如何“进化”,实际微软是并不知道的呢?而且研究人员表示,他们“并无法访问GPT-4庞大训练数据的全部细节”,实际机器学习,不就是利用神经网络分析海量的数据,找出其内在联系,组合成新的知识吗?
目前可能是GPT-4的进化太快,微软内部实际也有很多不同甚至矛盾的声音,比如OpenAI之父塞缪尔·奥尔特曼一再强调GPT-4的局限性,并说“我们还没有真正的AGI”,微软也称自己并不专注于尝试去实现AGI。
|国内离GPT-4多远?先做出GPT-3.5
数智前线获悉,国内几家大型互联网公司和人工智能企业接到了客户密集的问询,了解ChatGPT和大模型相关的内容。尤其是行业龙头和大企业,都有一种焦虑:国内的大模型进展如何,技术是否跟得上?
“过去,大家普遍认为,国内与海外在人工智能方面的进展,相差不大,但ChatGPT出来之后,大家有点措手不及。”一位互联网大厂人士告诉数智前线,大模型参数超过千亿之后,实现了质变,让人工智能初步具备了逻辑和推理能力。
ChatGPT带来的这种紧迫感无处不在。尽管效果上与ChatGPT还有很大差距——即便是谷歌和Facebook等海外巨头,在大模型上的表现也不如OpenAI——但国内大厂在人工智能大模型上的布局早已经开始。包括阿里的M6大模型、百度的文心大模型、华为的盘古大模型、腾讯的混元大模型以及智源的悟道大模型,其参数量都在千亿规模以上,而且都是多模态。
国内厂商在人工智能领域的努力有目共睹。百度在过去几个月,加班加点,追赶ChatGPT的进度。3月中旬,百度推出的类ChatGPT产品“文心一言”已经对外开放测试,尽管在效果上不如ChatGPT,但也引起了国内用户和企业的积极尝试,数万家企业申请调用API服务,服务器一度被挤爆。
腾讯也在公开回应中明确表示,腾讯在相关方向上已有布局,专项研究也在有序推进。3月22日的腾讯财报会上,总裁刘炽平也回应了投资者关切,称腾讯将积极投入资源来构建基础模型,并在未来将其应用到腾讯的每一个业务线中。
腾讯做事一向比较低调,但其实腾讯在人工智能上的布局并不少,时间也不短。据数智前线获悉,目前腾讯旗下主要有三大人工智能实验室:优图实验室主打计算机视觉和产业AI应用,WeChat AI专注开发语音AI,AI Lab则专注于基础研究和应用探索的结合。
在腾讯云智能之前披露的“四级加速架构”里,不仅有最底层的算力(自研AI芯片加速算力效能),也有开发层的混元大模型,并通过腾讯云TI平台提供多元行业大模型精调解决方案,上面还有即插即用的标准化应用行业和行业解决方案,已经形成了一套从基础算力到算法模型到上层应用完整的链条。
具体到外界非常关注的模型层,腾讯在2022年对外公布过AI大模型“混元”,取”混沌初始“之意,包含了CV(机器视觉)大模型,NLP(自然语言处理)大模型以及多模态大模型,覆盖了业内主流的研究方向,先后在中文语言理解权威评测集合CLUE与VCR、MSR-VTT,MSVD等多个权威多模态数据集榜单中登顶,实现跨模态领域的大满贯。
混元大模型的优势在于,一是腾讯在人工智能领域的技术积累和储备,让其在多个细分赛道获得了突破。比如在NLP领域,依托于腾讯的太极机器学习平台,腾讯在去年推出了万亿中文NLP预训练模型HunYuan-NLP-1T,这个模型在最新的自然语言理解任务榜单CLUE上斩获三个榜首。
二是腾讯有海量应用场景。除常规公开数据集之外,“混元”大模型还学习了商业领域特有的文本数据集。相较于业界其他AI大模型,“混元”能够更好地理解各种长度文本信息,应对搜索、广告、新闻、问答等多样化的场景任务,在阅读理解、知识图谱相关的下游任务中也更加具有优势。
如今,在ChatGPT的声浪中,国内大厂们正在加速行动。据数智前线获悉,算力和数据作为大模型的关键要素之一,国内不少企业在大量购买英伟达GPU,同时也有些巨头正在寻找高质量的中文数据,为训练效果更佳的大模型做准备。
“最重要的事情就是现在能把GPT-3.5复现出来。”印奇说,“GPT-3.5是更重要的点,至少让大家在共同的基准上,这样后续无论是应用的创新、对技术的创新各方面至少有感觉。”
|GPT6应用具有怎样的想象力?
搜索一定是落地的第一个场景,办公软件,比如office365;电子邮件、视频会议也是生成内容类的场景。此外,像服务机器人、智能客服也是非常好的应用领域。
现在其实有两个革命,一个是能源革命,基于锂电池,从过去的化石能源到我们的现在的锂电能源。另一个革命就是以ChatGPT为代表的AGI通用人工智能,未来在有了更灵敏的机械反馈后,机器人就是最大的一个应用场景。
智能数字人一定会比机器人更先应用。因为机器人受掣肘的地方比较多,包括续航、关节自由度等等,落地的困难要大很多。如果是数字世界里面的一个数字人,它的到来可能就会快很多,比如主持人、直播带货、数字明星等等。
此外,对游戏行业的影响也很大,特别是能够直接大幅降低游戏的开发成本。用AI画图能够极大提高游戏创意师的工作效率。
未来AI机器能够替代很多简单的工作,所以人的创意,人的思想就变得特别重要。所以我们觉得对于内容创意者会带来特别大的需求提升。



